Async Elixir Telemetry
Learn how to use Telemetry and GenServer in Elixir to wire up analytics without sacrificing app responsiveness.
One of the most fantastic abstractions used in many Elixir applications is provided by the Telemetry library. It allows libraries to emit arbitrary events that other code can subscribe to. This is similar to a Node.js event emitter, but make it global.
While this doesn’t seem very important at first glance, the power of Telemetry comes from its vast adoption. Packages such as Phoenix (the popular web framework), Oban (the popular background job framework), and Finch (the HTTP request library used by Req) all emit events through Telemetry.
Typically, Telemetry is used to publish metrics through systems like Prometheus, StatsD, and CloudWatch. These solutions often rely on the telemetry_metrics library and consume numeric values included in many telemetry events.
Telemetry also tends to be used for request logging, since every Phoenix request emits a series of events containing the requested path, method, IP, and response status code. It’s a really convenient way to plug in logging services without altering router and controller code.
The most important limitation to consider when using telemetry can be found in the readme:
The
handle_eventcallback of each handler is invoked synchronously on eachtelemetry:executecall. Therefore, it is extremely important to avoid blocking operations. If you need to perform any action that is not immediate, consider offloading the work to a separate process (or a pool of processes) by sending a message.
This brings me to the topic of today’s post, but first I want to set some context.
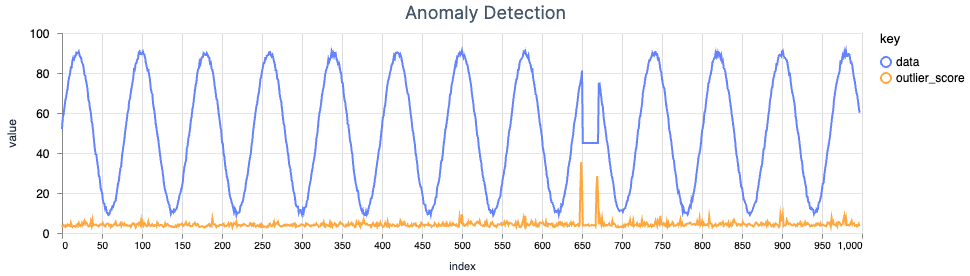
Random Cut Forests
Anomaly detection is a complicated and well-researched area of computer science. With all of the machine learning hype of recent months, I wanted to build something using my favorite programming language, Elixir.
Mitigating Server-Side Request Forgery
Server-Side Request Forgery (SSRF) vulnerabilities allow an attacker to cause a server application to perform an unintended request. When exploited, the server could leak sensitive internal information or perform dangerous actions. Because this vulnerability depends on the capabilities of the server application, the potential impact of an attack can vary.
Webhooks are among the most common features that introduce SSRF vulnerabilities to applications. They combine arbitrary user input (the webhook URL) with the ability to make requests from the backend. It’s important to consider this threat when building and operating webhook systems.
The attack
For the purposes of this post, imagine we have a web application that is able to perform outbound requests to a user-configured endpoint.
Adding soft delete to a Phoenix Commanded (CQRS) API
Part two in my series on Elixir’s Commanded library. Part one can be found here.
Context
In the previous post, I converted a vanilla Phoenix API to CQRS with Commanded.
This application writes to the database using the commanded_ecto_projections hex package, which subscribes to events and projects their state into tables managed by the Ecto database library.
Since the core data model of this application is an append-only (immutable) log, the events can be replayed and the read model can be dramatically changed using existing data.
Goal
Implement a soft delete in the API, allowing items to be restored after deletion.
Follow along with what I learned while iterating on a project named todo_backend_commanded. Its git history shows the steps involved to implement soft delete and restore functionality.